Quick-start Guide¶
This guide is walkthrough for the DEBrowser from start to finish.
Getting Started¶
First off, we need to install R package of DEBrowser from bioconductor:
source("https://bioconductor.org/biocLite.R")
biocLite("debrowser")
One you have installed the R package, you can call these R commands:
library(debrowser)
startDEBrowser()
Note
For more information on installing DEBrowser locally, please consult our Installation Guide.
Once you’ve made your way to the website, or you have a local instance of DEBrowser running, you will be greeted with data loading section:
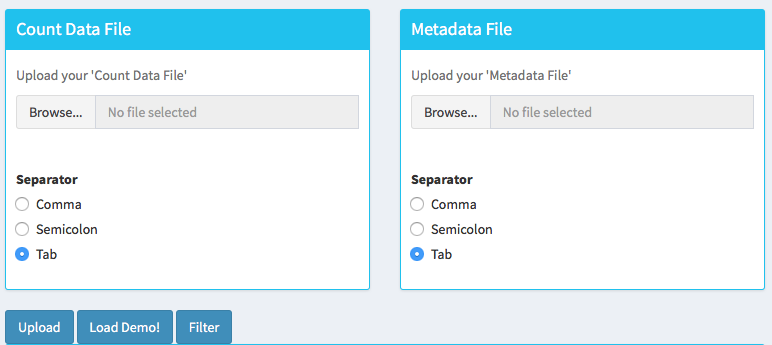
To begin the analysis, you need to upload your count data file (comma or semicolon separated (CSV), and tab separated (TSV) format) to be analyzed and choose appropriate separator for the file (comma, semicolon or tab).
If you do not have a dataset to upload, you can use the built in demo data file by clicking on the ‘Load Demo (Vernia et al.)!’ button. To view the entire demo data file, you can download this demo set. For another example, try our full dataset (Vernia et. al) .
The structure of the count data files are shown below:
| gene | exp1 | exp2 | cont1 | cont2 |
|---|---|---|---|---|
| DQ714 | 0.00 | 0.00 | 0.00 | 0.00 |
| DQ554 | 0.00 | 0.00 | 0.00 | 0.00 |
| AK028 | 2.00 | 1.29 | 0.00 | 0.00 |
Tip
DEBrowser also accepts count data files via hyperlink, for more information please see the autoload data via hyperlink section.
In addition to the count data file; you might need to upload metadata file to correct for batch effects or any other normalizing conditions you might want to address that might be within your results. To handle for these conditions, simply create a metadata file by using the example table at below or download sample file from this link. Metadata file also simplifies condition selection for complex data. The columns you define in this file can be selected in condition selection page. Make sure you have defined two conditions per column. If there are more than two conditions in a column, those can be defined empty. Please note that, if your data is not complex, metadata file is optional, you don’t need to upload.
| sample | batch | condition |
|---|---|---|
| exper_rep1 | 1 | A |
| exper_rep2 | 2 | A |
| exper_rep3 | 1 | A |
| control_rep1 | 2 | B |
| control_rep2 | 1 | B |
| control_rep3 | 2 | B |
Metadata file can be formatted with comma, semicolon or tab separators similar to count data files. These files used to establish different batch effects for multiple conditions. You can have as many conditions as you may require, as long as all of the samples are present.
Note
The example above would result in the first set of conditions as exper_rep1, exper_rep2, exper_rep3 from A and second set of conditions as control_rep1, control_rep2, control_rep3 from B as they correspond to those conditions in the condition column.
In the same way, ‘batch’ would have the first set as exper_rep1, exper_rep3, control_rep2 from 1 and second set as exper_rep2, control_rep1, control_rep3 from 2 as they correspond to those conditions in the batch column.
Once the count data and metadata files have been loaded in DEBrowser, you can click upload button to visualize your data as shown at below:
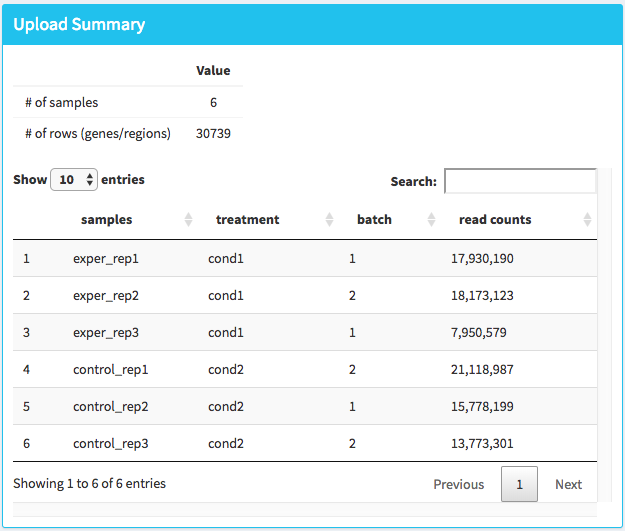
After loading the gene quantification file, and if specified the metadata file containing your batch correction fields, you then have the option to filter low counts and conduct batch effect correction prior to your analysis. Alternatively, you may skip these steps and directly continue with differential expression analysis or view quality control (QC) information of your dataset.
Low Count Filtering¶
In this section, you can simultaneously visualize the changes of your dataset while filtering out the low count genes. Choose your filtration criteria from Filtering Methods box which is located just center of the screen. Three methods are available to be used:
- Max: Filters out genes where maximum count for each gene across all samples are less than defined threshold.
- Mean: Filters out genes where mean count for each gene are less than defined threshold.
- CPM: First, counts per million (CPM) is calculated as the raw counts divided by the library sizes and multiplied by one million. Then it filters out genes where at least defined number of samples is less than defined CPM threshold.
After selection of filtering methods and entering threshold value, you can proceed by clicking Filter button which is located just bottom part of the Filtering Methods box. On the right part of the screen, your filtered dataset will be visualized for comparison as shown at figure below.
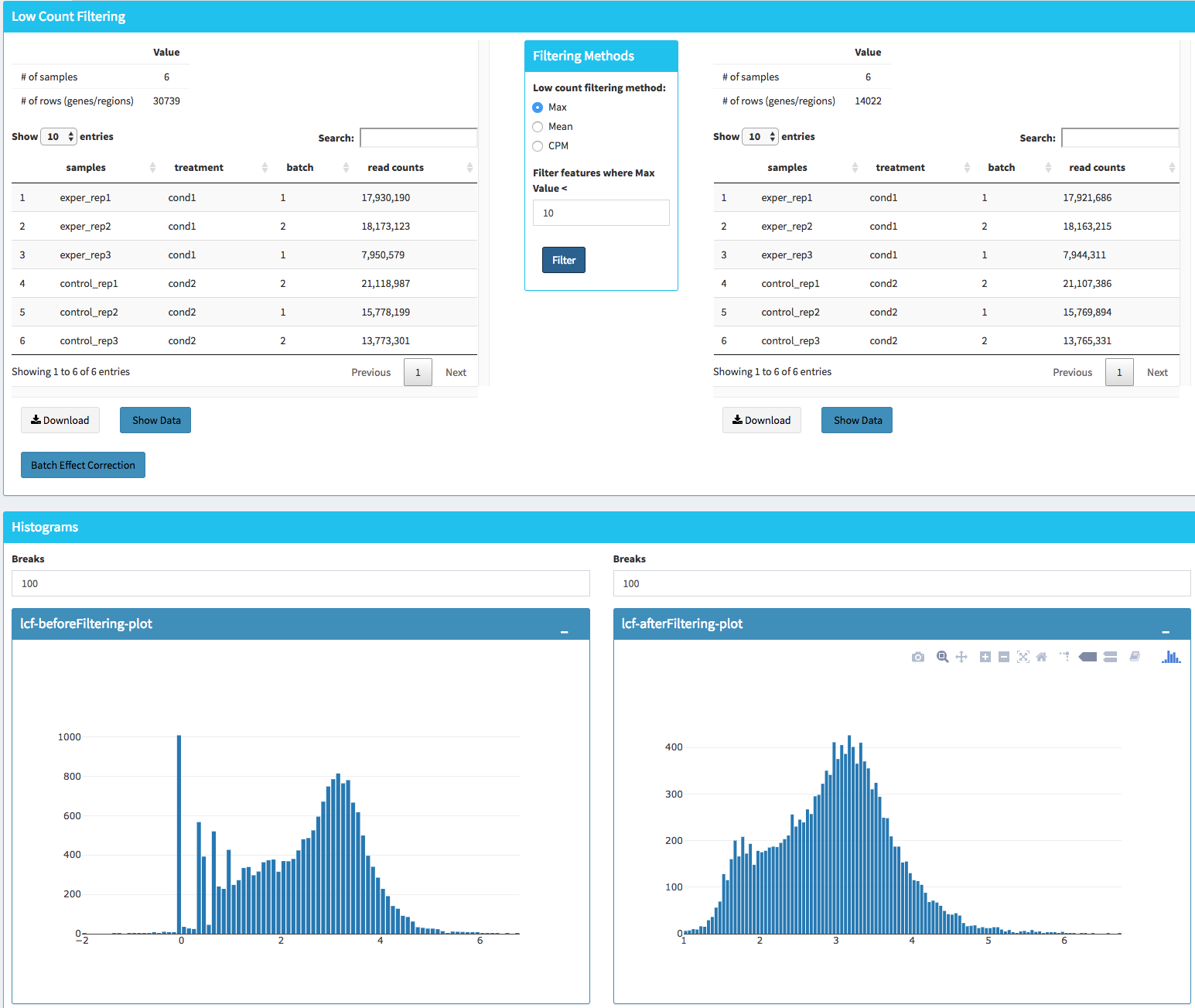
You can easily compare following features, before and after filtering:
- Number of genes/regions.
- Read counts for each sample.
- Overall histogram of the dataset.
- gene/region vs samples data
Important
To investigate the gene/region vs samples data in detail as shown at below, you may click the Show Data button, located bottom part of the data tables. Alternatively, you may download all filtered data by clicking Download button which located next to Show Data button.

Afterwards, you may continue your analysis with Batch Effect Correction or directly jump to differential expression analysis or view quality control (QC) information of your dataset.
Batch Effect Correction and Normalization¶
If specified metadata file containing your batch correction fields, then you have the option to conduct batch effect correction prior to your analysis. By adjusting parameters of Options box, you can investigate your character of your dataset. These parameters of the options box are explained as following:
- Normalization Method: DEBrowser allows performing normalization prior the batch effect correction. You may choose your normalization method (among MRN (Median Ratio Normalization), TMM (Trimmed Mean of M-values), RLE (Relative Log Expression) and upperquartile), or skip this step by choosing none for this item. For our sample data, we are going to choose MRN normalization.
- Correction Method: DEBrowser uses ComBat (part of the SVA bioconductor package) or Harman to adjust for possible batch effect or conditional biases. For more information, you can visit following links for documentation: ComBat, Harman For our sample data, Combat correction was selected.
- Treatment: Please select the column that is specified in metadata file for comparison, such as cancer vs control. It is named treatment for our sample metadata.
- Batch: Please select the column name in metadata file which differentiate the batches. For example in our metadata, it is called batch.
Upon clicking submit button, comparison tables and plots will be created on the right part of the screen as shown below.

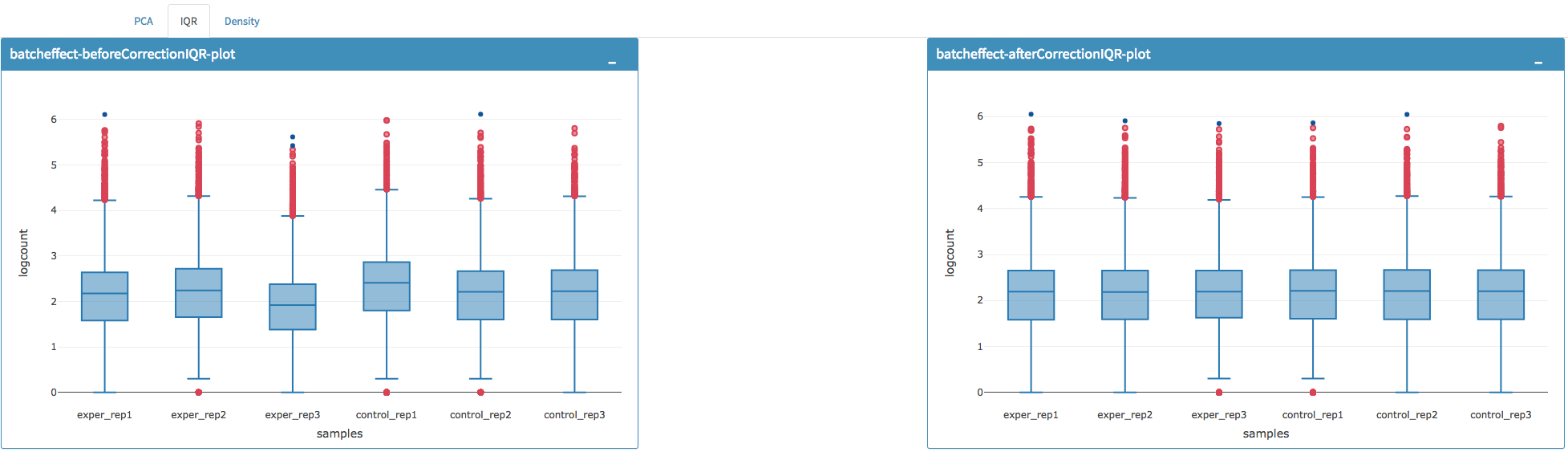
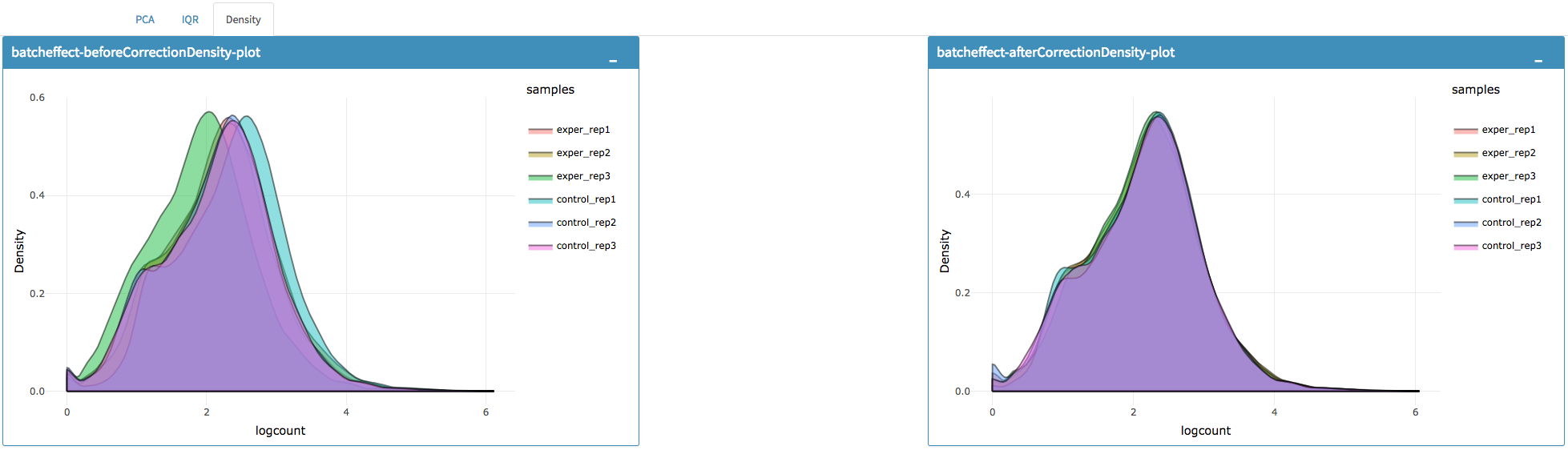
You can investigate the changes on the data by comparing following features:
- Read counts for each sample.
- PCA, IQR and Density plot of the dataset.
- Gene/region vs samples data
Tip
You can investigate the gene/region vs samples data in detail by clicking the Show Data button, or download all corrected data by clicking Download button.
Since we have completed batch effect correction and normalization step, we can continue with one of the following options: ‘Go to DE Analysis’ and, ‘Go to QC plots!’. First option takes you to page where differential expression analyses are conducted with DESeq2, EdgeR or Limma. The second option, ‘Go to QC plots!’, takes you to a page where you can view quality control metrics of your data by PCA, All2All, Heatmap, Density, and IQR plots.
DE Analysis¶
The first option, ‘Go to DE Analysis’, takes you to the next step where differential expression analyses are conducted.
Sample Selection: In order to run DE analysis, you first need to select the samples which will be compared. To do so, click on “Add New Comparison” button, and choose Select Meta box as treatment to simplify fill
Condition 1andCondition 2based on the treatment column of the metadata as shown below.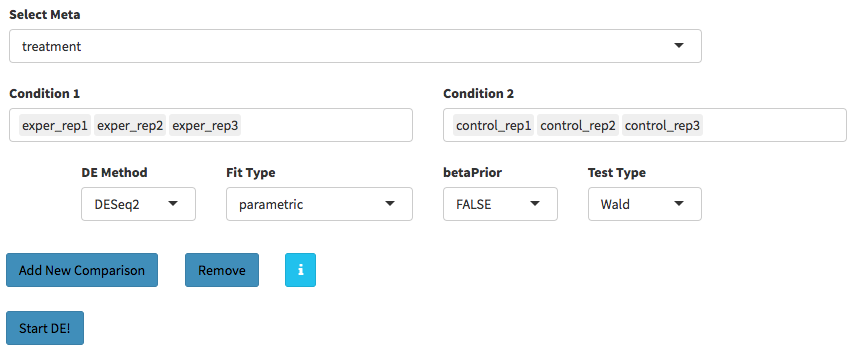
If you need to remove samples from a condition, simply select the sample you wish to remove and hit the delete/backspace key. In case, you need to add a sample to a condition you can click on one of the condition text boxes to bring up a list of samples and then click on the sample you wish to add from the list and it will be added to the textbox for that comparison.
Tip
You can add multiple conditions to compare by clicking on “Add New Comparison” button, and view the results separately after DE analysis.
- Method Selection: Three DE methods are available for DEBrowser: DESeq2, EdgeR, and Limma. DESeq2 and EdgeR are designed to normalize count data from high-throughput sequencing assays such as RNA-Seq. On the other hand, Limma is a package to analyse of normalized or transformed data from microarray or RNA-Seq assays. We have selected DESeq2 for our test sample and showed the related results at below.
After clicking on the ‘Submit!’ button, DESeq2 will analyze your comparisons and store the results into separate data tables. It is important to note that the resulting data produced from DESeq is normalized. Upon finishing the DESeq analysis, a result table will appear which allows you to download the data by clicking “Download” button. To visualize the data with interactive plots please click on “Go to Main Plots!” button.
The Main Plots of DE Analysis¶
Upon finishing the DESeq analysis, please click on Go to Main Plots! button which will open Main Plots tab where you will be able to view the interactive plots.

The page will load with Scatter Plot. You can switch to Volcano Plot and MA Plot by using Plot Type section at the left side of the menu. Since these plots are interactive, you can click to zoom button on the top of the graph and select the area you would like to zoom in by drawing a rectangle. Please see the plots at below:

A. Scatter plot, B. Volcano plot, C. MA plot
You can easily track the plotting parameters by checking Plot Information box as shown at below. Selected DE parameters, chosen dataset, compared conditions, and normalization method are listed. Additionally, heatmap parameters (scaled, centered, log, pseudo-count) could be simply followed by this info box.

Tip
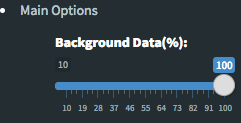
Please keep in mind that to increase the performance of the generating graph, by default 10% of non-significant(NS) genes are used to generate plots. You might show all NS genes by please click Main Options button and change Background Data(%) to 100% on the left sidebar.
You can hover over the scatterplot points to display more information about the point selected. A few bargraphs will be generated for the user to view as soon as a scatterplot point is hovered over.
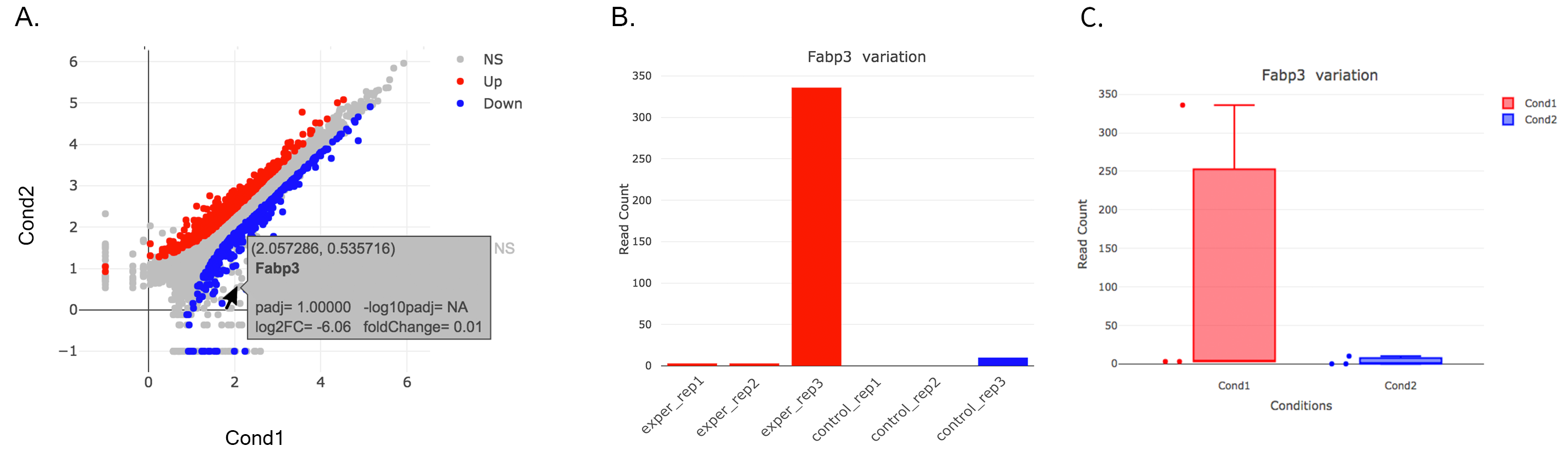
A. Hover on Fabp3 gene, B. Read Counts vs Samples, C. Read Counts vs Conditions
You also have a wide array of options when it comes to fold change cut-off levels, p-adjusted (padj) cut-off values, which comparison set to use, and dataset of genes to analyze.
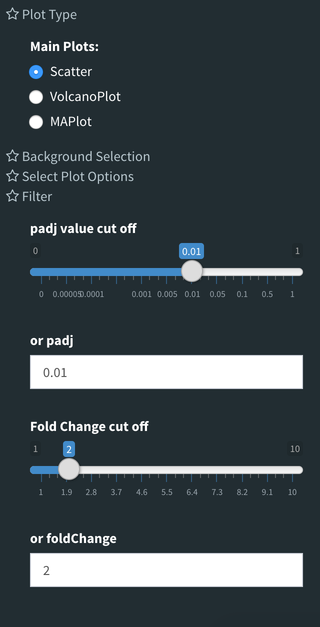
Tip
It is important to note that when conducting multiple comparisons, the comparisons are labeled based on the order that they are input. If you don’t remember which samples are in your current comparison you can always view the samples in each condition at the top of the main plots.

After DE analysis, you can always download the results in CSV format by clicking the Download Data button located under the Data Options. You can also download the plot or graphs by clicking on the download button at top of each plot or graph.
The Heatmap of DE Analysis¶
Once you’ve selected a specific region on Main Plots (Scatter, Volcano or MA plot), a new heatmap of the selected area will appear just next to your plot. If you want to hide some groups (such as Up, Down or NS based on DE analysis), just click on the group label on the top right part of the figure. In this way, you can select a specific part of the genes by lasso select or box select tools that includes only Up or Down Regulated genes. As soon as you completed your selection, heatmap will be created simultaneously. Please find details about heatmaps on Heatmaps section.
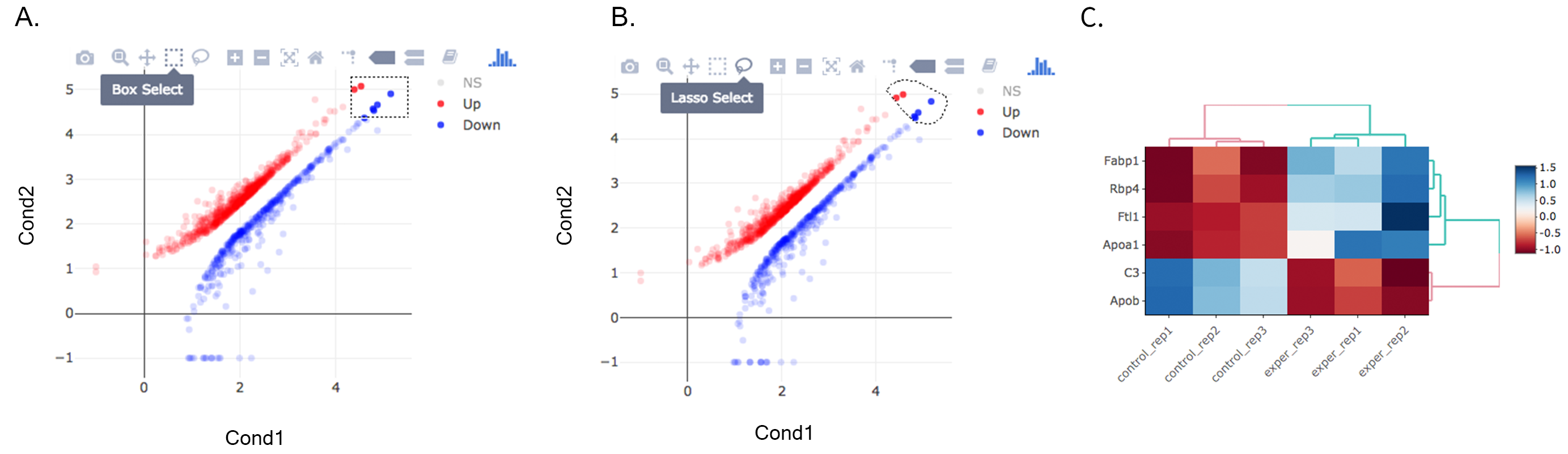
A. Box Selection, B. Lasso Selection, C. Created heatmap based on selection
Tip
We strongly recommend normalization before plotting heatmaps. To normalize, please change the parameters that are located under: Data options -> Normalization Methods and select the method from the dropdown box.
GO Term Plots¶
The next tab, ‘GO Term’, takes you to the ontology comparison portion of DEBrowser. From here you can select the standard dataset options such as p-adjust value, fold change cut off value, which comparison set to use, and which dataset to use on the left menu. In addition to these parameters, you also can choose from the 4 different ontology plot options: ‘enrichGO’, ‘enrichKEGG’, ‘Disease’, and ‘compareCluster’. Selecting one of these plot options queries their specific databases with your current DESeq results.
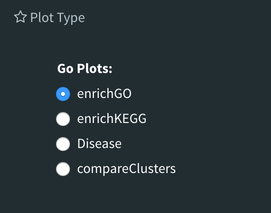
Your GO plots include:
- enrichGO - use enriched GO terms
- enrichKEGG - use enriched KEGG terms
- Disease - enriched for diseases
- compareClusters - comparison of your clustered data
The types of plots you will be able to generate include:
Summary plot:
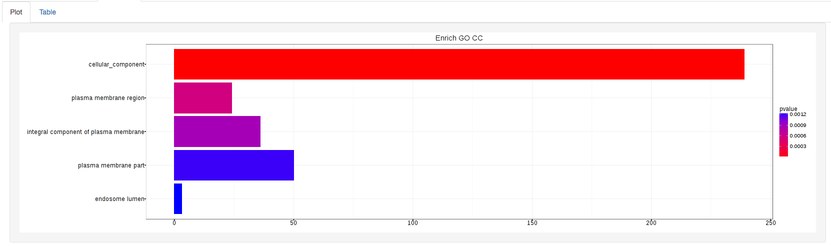
GOdotplot:
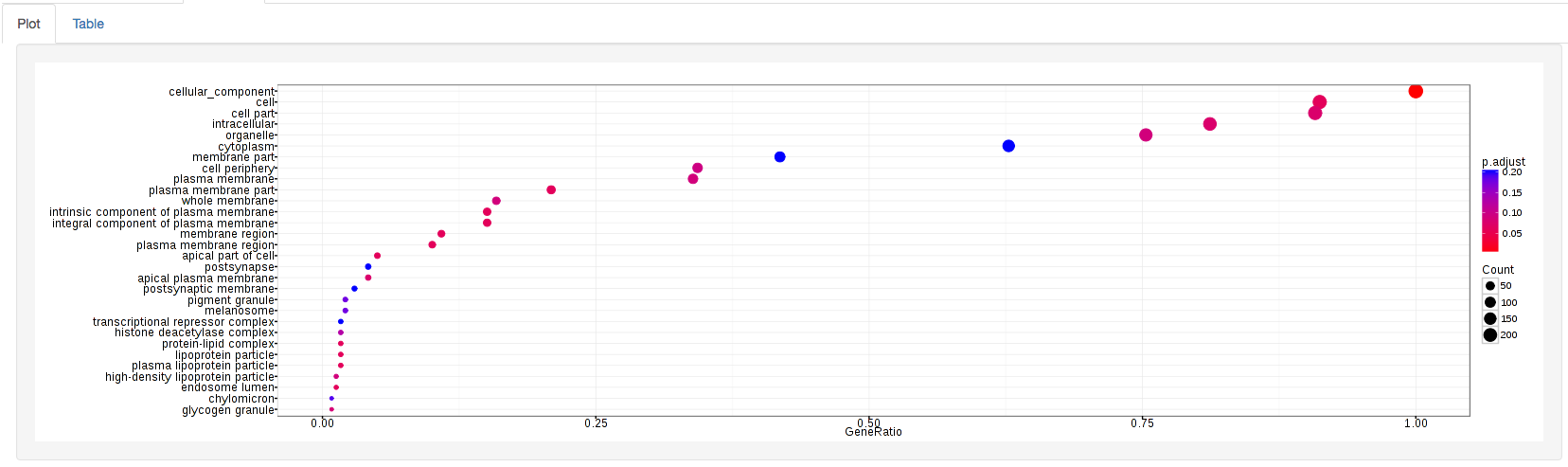
Changing the type of ontology to use will also produce custom parameters for that specific ontology at the bottom of the left option panel.
Once you have adjusted all of your parameters, you may hit the submit button in the top right and then wait for the results to show on screen!
Data Tables¶
The last tab at the top of the screen displays various different data tables. These datatables include:
- All Detected
- Up Regulated
- Down Regulated
- Up+down Regulated
- Selected scatterplot points
- Most varied genes
- Comparison differences
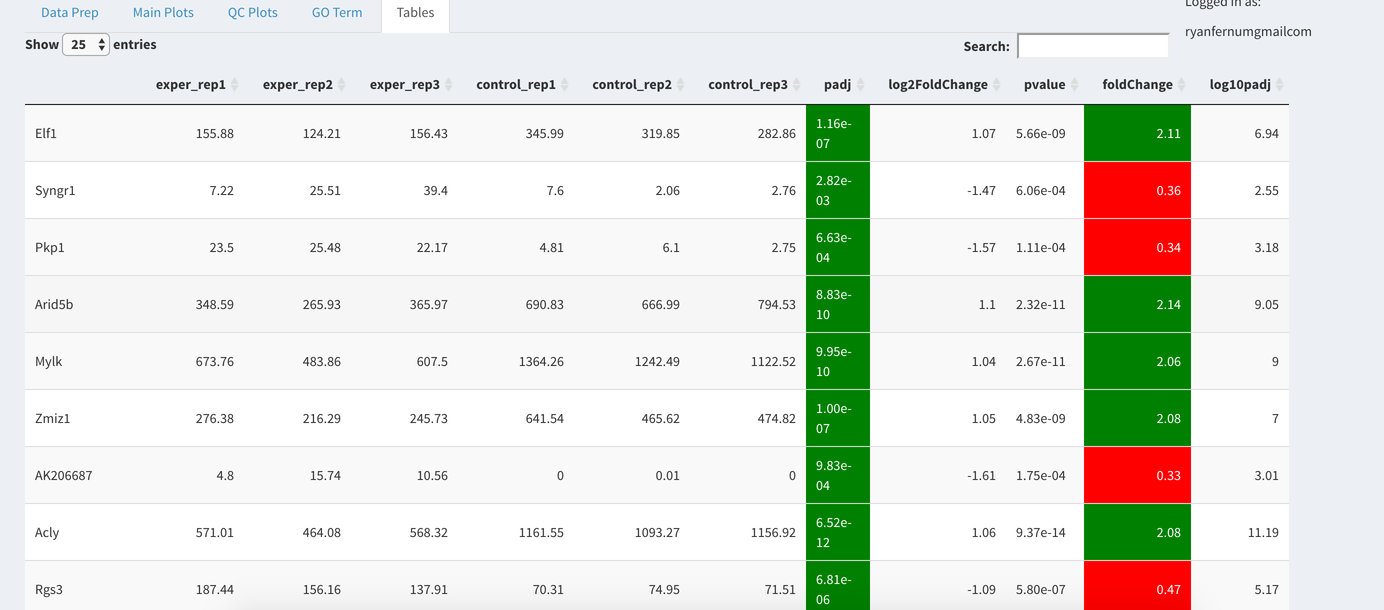
All of the tables tables, except the Comparisons table, contain the following information:
- ID - The specific gene ID
- Sample Names - The names of the samples given and they’re corresponding tmm normalized counts
- Conditions - The log averaged values
- padj - padjusted value
- log2FoldChange - The Log2 fold change
- foldChange - The fold change
- log10padj - The log 10 padjusted value
The Comparisons table generates values based on the number of comparisons you have conducted. For each pairwise comparison, these values will be generated:
- Values for each sample used
- foldChange of comparison A vs B
- pvalue of comparison A vs B
- padj value of comparison A vs B
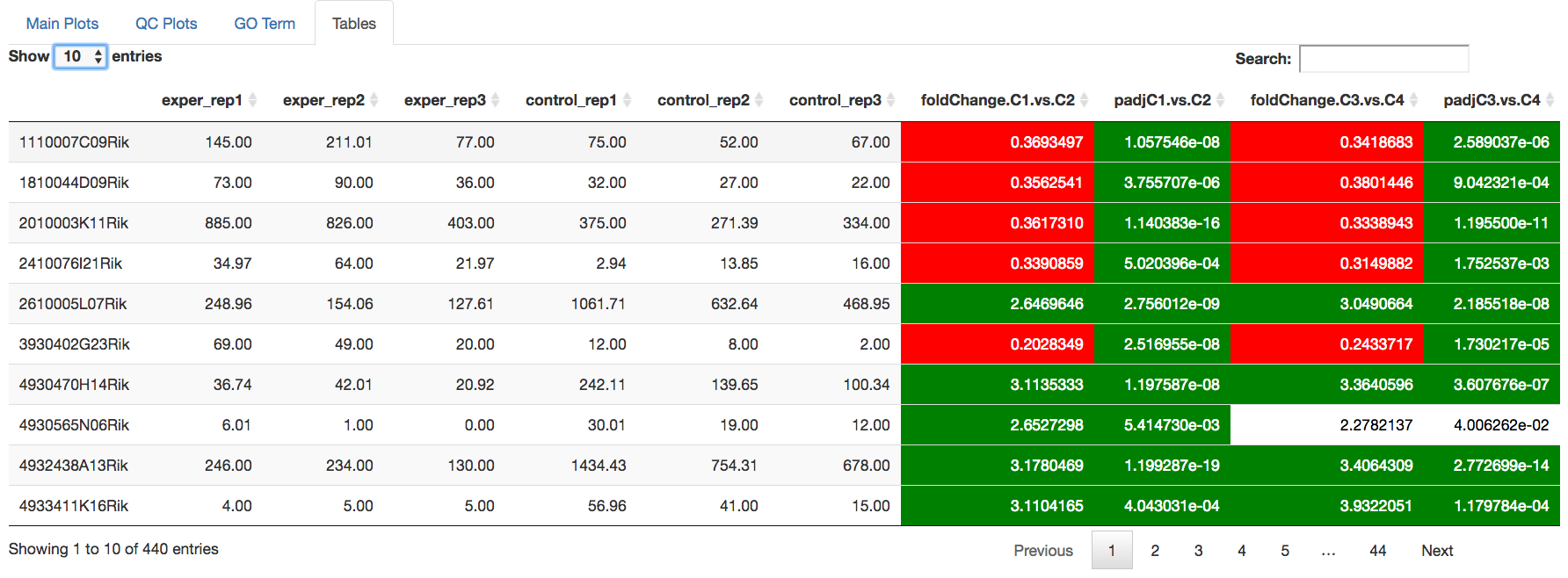
You can further customize and filter each specific table a multitude of ways. For unique table or dataset options, select the type of table dataset you would like to customize on the left panel under ‘Choose a dataset’ to view it’s additional options. All of the tables have a built in search function at the top right of the table and you can further sort the table by column by clicking on the column header you wish to sort by. The ‘Search’ box on the left panel allows for multiple searches via a comma-separated list. You can additionally use regex terms such as “^al” or “*lm” for even more advanced searching. This search will be applied to wherever you are within DEBrowser, including both the plots and the tables.
Tip
If you enter more than three lines of genes, search tool will automatically match the beginning and end of the search phrases. Otherwise it will find matched substrings in the gene list.
You can also view specific tables of your input data for each type of dataset available and search for a specific geneset by inputting a comma-separated list of genes or regex terms to search for in the search box within the left panel. To view these tables, you must select the tab labeled ‘Tables’ as well as the dataset from the dropdown menu on the left panel.
Tip
If you ever want to change your parameters, or even add a new set of comparisons, you can always return to the Data Prep tab to change and resubmit your data.
Quality Control Plots¶
Selecting the ‘QC Plots’ tab will take you to the quality control plots section. The page opens with a Principal Component Analysis (PCA) plot and users can also view a All2All, heatmap, IQR, and density by choosing Plot Type in the left panel. Here the dataset being used in the plots, depends on the parameters you selected in the left panel. Therefore, you are able to adjust the size of the plots under ‘width’ and ‘height’ as well as alter a variety of other parameters to adjust the specific plot you’re viewing.
The All2All plot displays the correlation between each sample, Heatmap shows a heatmap representation of your data, IQR displays a barplot displaying the IQR between samples, and Density will display an overlapping density graph for each sample. You also have the ability to select the type of clustering and distance method for the heatmap produced to further customize your quality control measures. Users also have the option to select which type of normalization methods they would like to use for these specific plotting analysis within the left menu.
Ploting Options
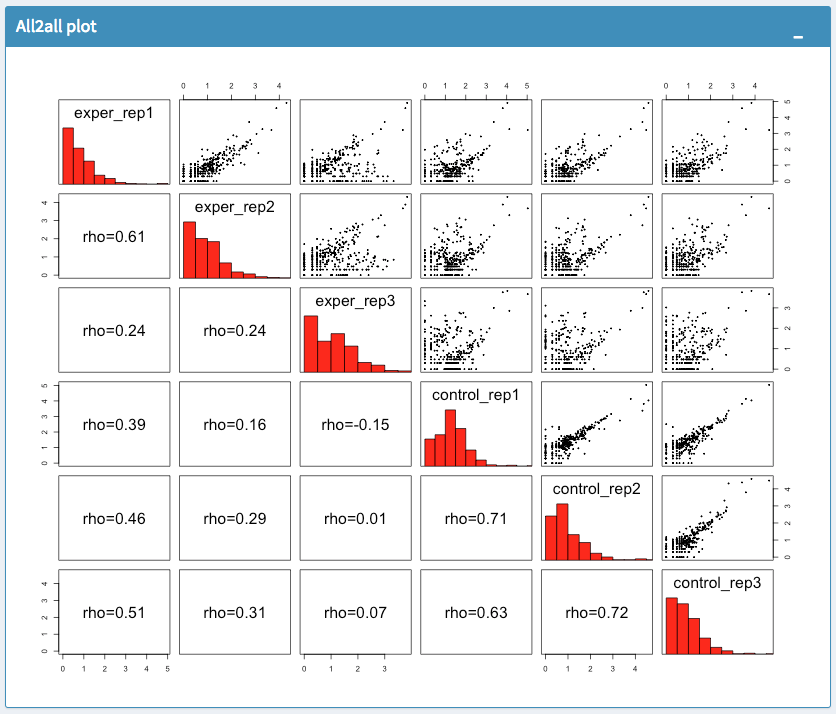
All2All Plot
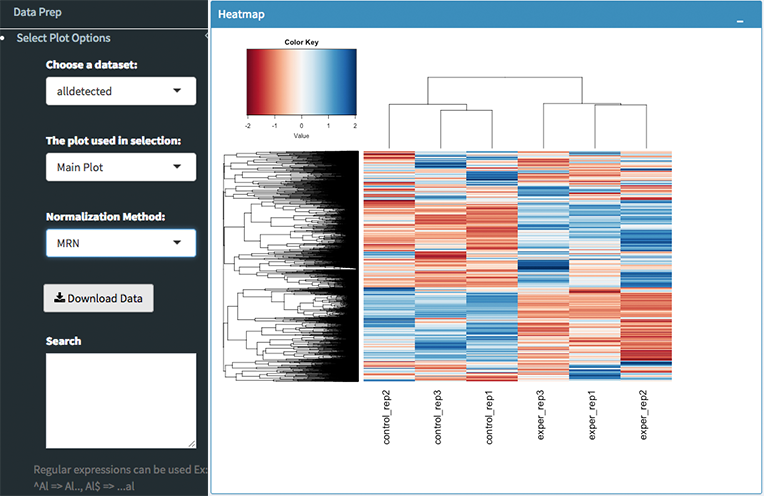
Heatmap Options to Normalize All Detected Data and Created Heatmap
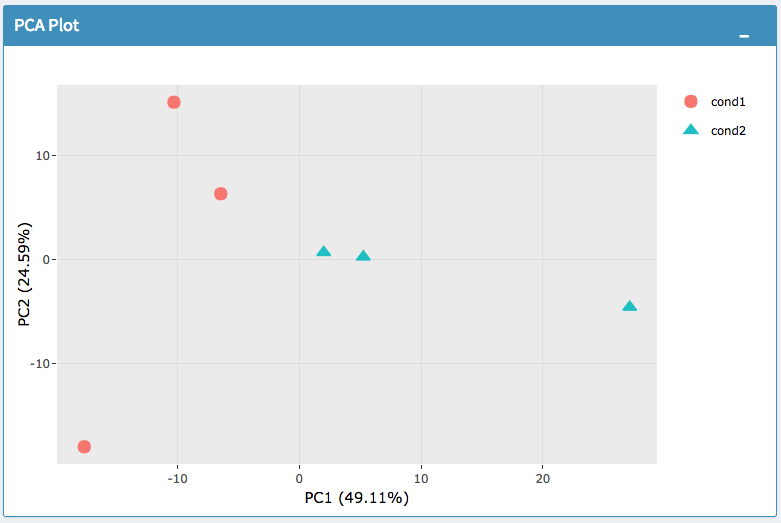
PCA Plot
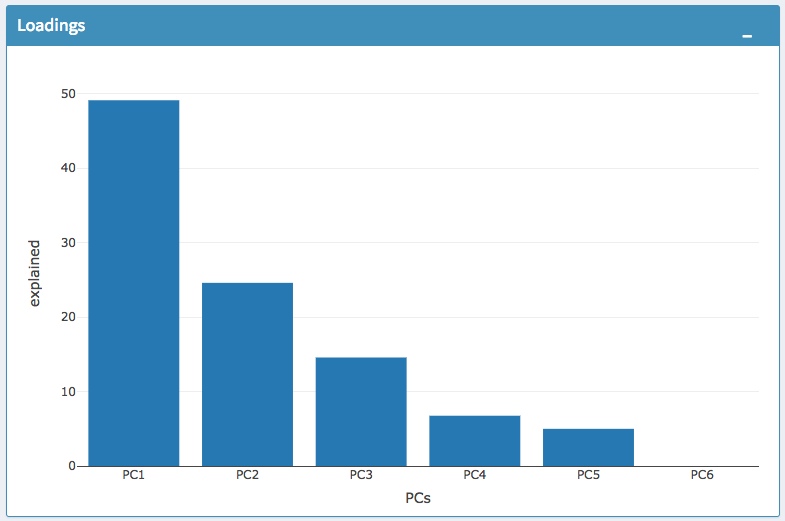
PCA Loadings
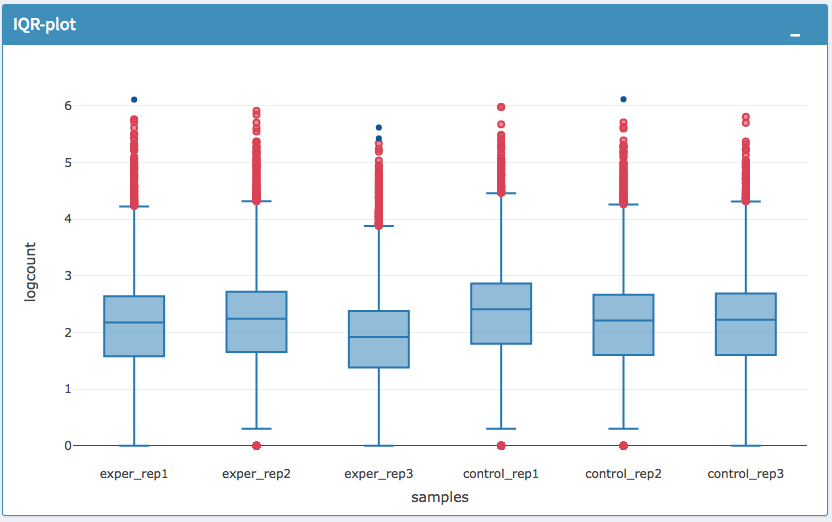
IQR Plot Before Normalization
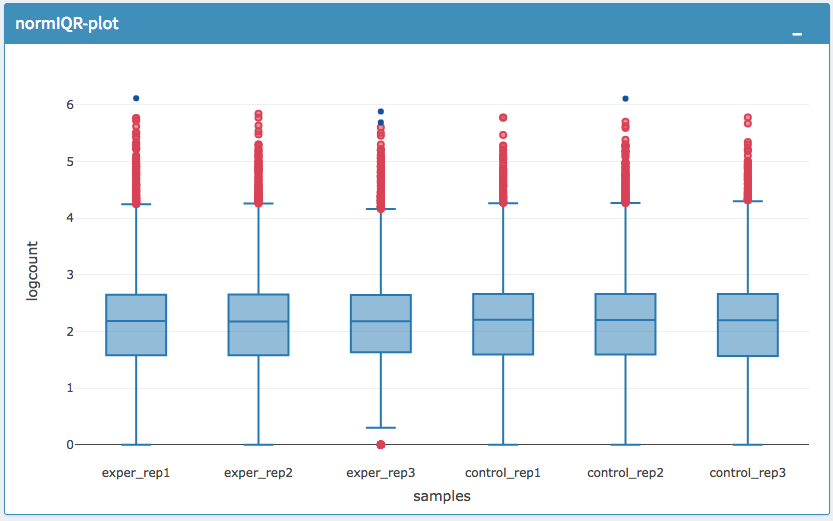
IQR Plot After Normalization
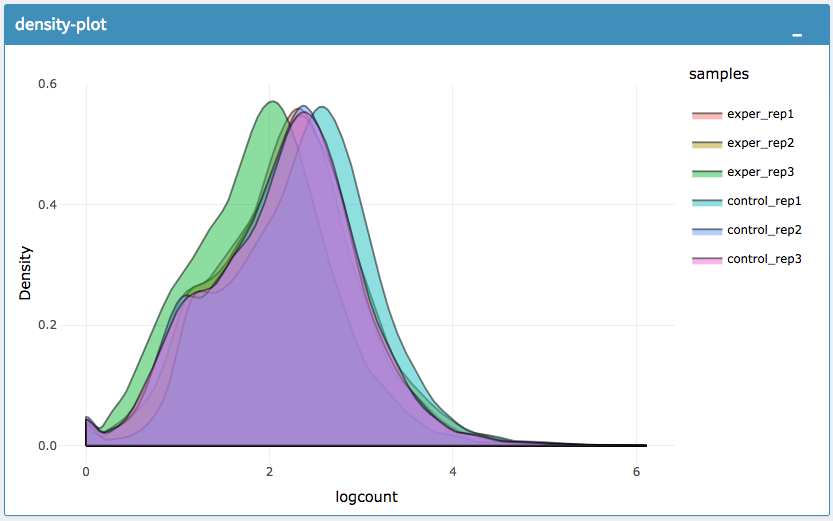
Density Plot Before Normalization
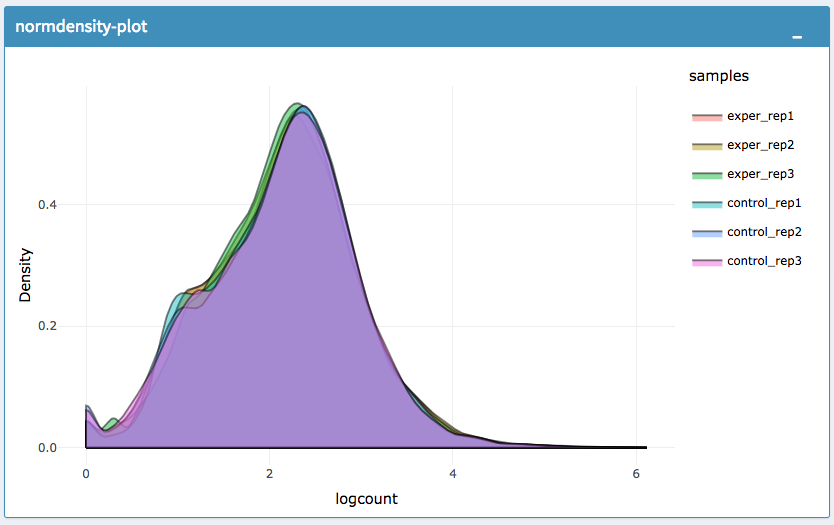
Density Plot After Normalization
Note
Each QC plot also has options to adjust the plot height and width, as well as a download button for a png output located above each plot.
For the Heatmap, you can also view an interactive session of the heatmap by selecting the ‘Interactive’ checkbox before submitting your heatmap request. Make sure that before selecting the interactive heatmap option that your dataset being used is ‘Up+down’. Just like in the Main Plots, you can click and drag to create a selection. To select a specific portion of the heatmap, make sure to highlight the middle of the heatmap gene box in order to fully select a specific gene. This selection can be used later within the GO Term plots for specific queries on your selection. For find more details please click Heatmaps section.
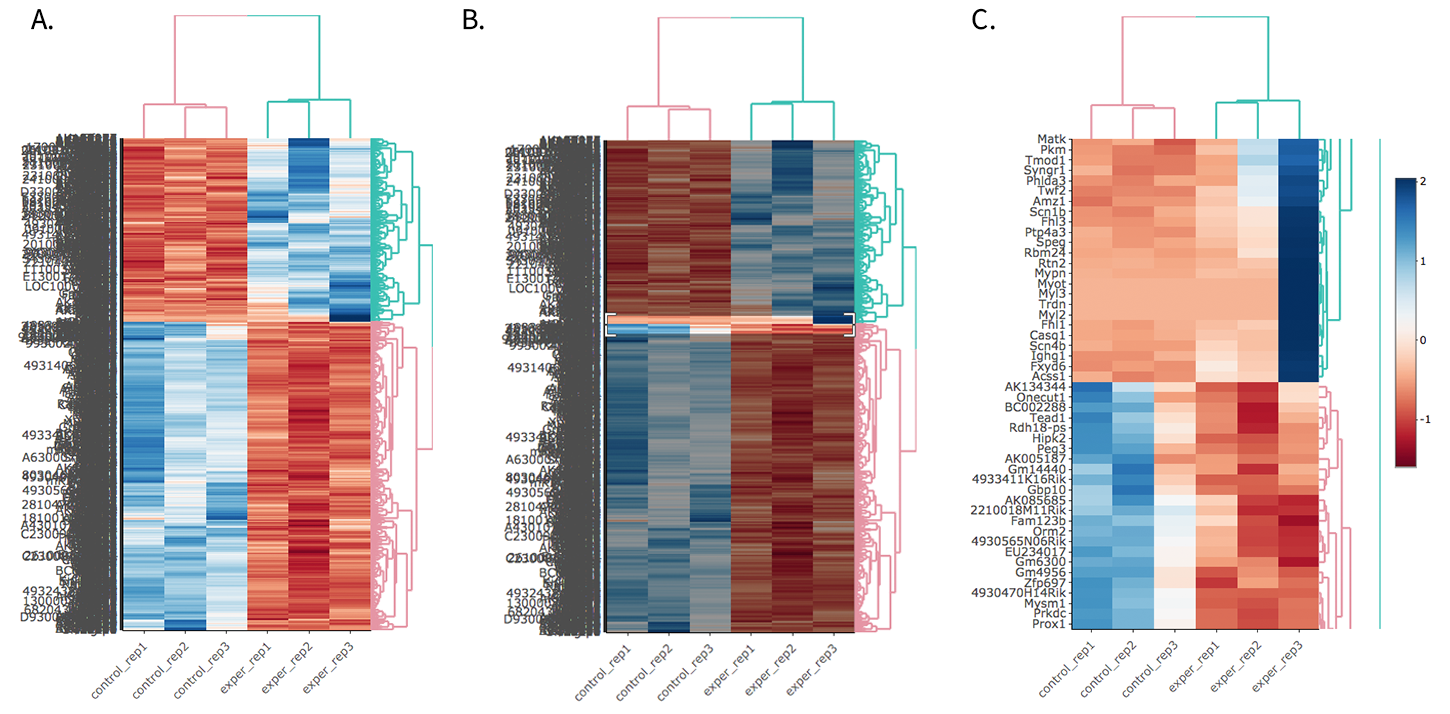
- Before Selection B. Selection of area with zoom tool C. Zoomed heatmap region which allows better viewing resolution.
Autoload Data via Hyperlink¶
DEBrowser also accepts TSV’s via hyperlink by following conversion steps. First, using the API provided by Dolphin, we will convert TSV into an html represented TSV using this website:
https://dolphin.umassmed.edu/public/api/
The two parameters it accepts (and examples) are:
- source=https://bioinfo.umassmed.edu/pub/debrowser/advanced_demo.tsv
- format=JSON
Leaving you with a hyperlink for:
https://dolphin.umassmed.edu/public/api/?source=https://bioinfo.umassmed.edu/pub/debrowser/advanced_demo.tsv&format=JSON
Next you will need to encode the url so you can pass it to the DEBrowser website. You can find multiple url encoders online, such as the one located at this link..
Encoding our URL will turn it into this:
http%3A%2F%2Fdolphin.umassmed.edu%2Fpublic%2Fapi%2F%3Fsource%3Dhttp%3A%2F%2Fbioinfo.umassmed.edu%2Fpub%2Fdebrowser%2Fadvanced_demo.tsv%26format%3DJSON
Now this link can be used in DEBrowser as:
https://debrowser.umassmed.edu:443/debrowser/R/
It accepts two parameters:
1. jsonobject= http%3A%2F%2Fdolphin.umassmed.edu%2Fpublic%2Fapi%2F%3Fsource%3Dhttp%3A%2F%2Fbioinfo.umassmed.edu%2Fpub%2Fdebrowser%2Fadvanced_demo.tsv%26format%3DJSON
2. title= no
The finished product of the link will look like this:
https://debrowser.umassmed.edu:443/debrowser/R/?jsonobject=https://dolphin.umassmed.edu/public/api/?source=https://bioinfo.umassmed.edu/pub/debrowser/advanced_demo.tsv&format=JSON&title=no
Inputting this URL into your browser will automatically load in that tsv to be analyzed by DEBrowser!